The need to analyze time-series or other forms of streaming data arises frequently in many different application areas. Examples include economic time-series like stock prices, exchange rates, or unemployment figures, biomedical data sequences like electrocardiograms or electroencephalograms, or industrial process operating data sequences like temperatures, pressures or concentrations. As a specific example, the figure below shows four data sequences: the upper two plots represent hourly physical property measurements, one made at the inlet of a product storage tank (the left-hand plot) and the other made at the same time at the outlet of the tank (the right-hand plot). The lower two plots in this figure show the results of applying the data cleaning filter outlierMAD from the R package pracma discussed further below. The two main points of this post are first, that isolated spikes like those seen in the upper two plots at hour 291 can badly distort the results of an otherwise reasonable time-series characterization, and second, that the simple moving window data cleaning filter described here is often very effective in removing these artifacts.

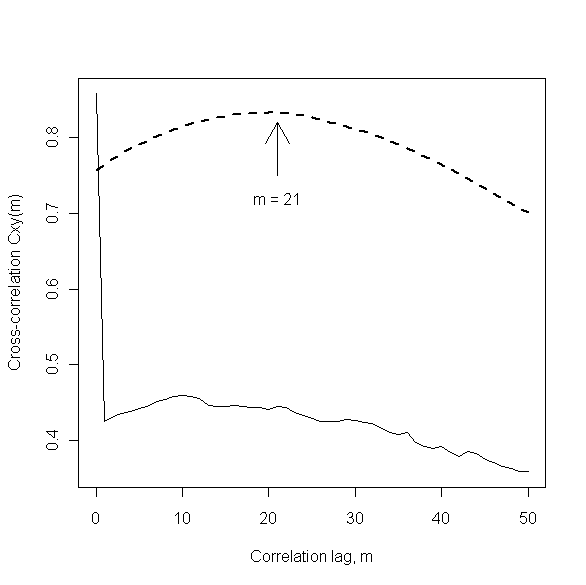
This example is discussed in more detail in Section 8.1.2 of my book Discrete-Time Dynamic Models, but the key observations here are the following. First, the large spikes seen in both of the original data sequences were caused by the simultaneous, temporary loss of both measurements and the subsequent coding of these missing values as zero by the data collection system. The practical question of interest was to determine how long, on average, the viscous, polymeric material being fed into and out of the product storage tank was spending there. A standard method for addressing such questions is the use of cross-correlation analysis, where the expected result is a broad peak like the heavy dashed line in the plot shown below. The location of this peak provides an estimate of the average time spent in the tank, which is approximately 21 hours in this case, as indicated in the plot. This result was about what was expected, and it was obtained by applying standard cross-correlation analysis to the cleaned data sequences shown in the bottom two plots above. The lighter solid curve in the plot below shows the results of applying exactly the same analysis, but to the original data sequences instead of the cleaned data sequences. This dramatically different plot suggests that the material is spending very little time in the storage tank: accepted uncritically, this result would imply severe fouling of the tank, suggesting a need to shut the process down and clean out the tank, an expensive and labor-intensive proposition. The main point of this example is that the difference in these two plots is entirely due to the extreme data anomalies present in the original time-series. Additional examples of problems caused by time-series outliers are discussed in Section 4.3 of my book Mining Imperfect Data.
One of the primary features of the analysis of time-series and other streaming data sequences is the need for local data characterizations. This point is illustrated in the plot below, which shows the first 200 observations of the storage tank inlet data sequence discussed above. All of these observations but one are represented as open circles in this plot, but the data point at k = 110 is shown as a solid circle, to emphasize how far it lies from its immediate neighbors in the data sequence. It is important to note that this point is not anomalous with respect to the overall range of this data sequence – it is, for example, well within the normal range of variation seen for the points from about k = 150 to k = 200 – but it is clearly anomalous with respect to those points that immediately precede and follow it. A general strategy for automatically detecting and removing such spikes from a data sequence like this one is to apply a moving window data cleaning filter which characterizes each data point with respect to a local neighborhood of prior and subsequent samples. That is, for each data point k in the original data sequence, this type of filter forms a cleaned data estimate based on some number J of prior data values (i.e., points k-J through k-1 in the sequence) and, in the simplest implementations, the same number of subsequent data values (i.e., points k+1 through k+J in the sequence).

The specific data cleaning filter considered here is the Hampel filter, which applies the Hampel identifier discussed in Chapter 7 of Exploring Data in Engineering, the Sciences and Medicine to this moving data window. If the kth data point is declared to be an outlier, it is replaced by the median value computed from this data window; otherwise, the data point is not modified. The results of applying the Hampel filter with a window width of J = 5 to the above data sequence are shown in the plot below. The effect is to modify three of the original data points – those at k = 43, 110, and 120 – and the original values of these modified points are shown as solid circles at the appropriate locations in this plot. It is clear that the most pronounced effect of the Hampel filter is to remove the local outlier indicated in the above figure and replace it with a value that is much more representative of the other data points in the immediate vicinity.

As I noted above, the Hampel filter implementation used here is that available in the R package pracma as procedure outlierMAD. I will discuss this R package in more detail in my next post, but for those seeking a more detailed discussion of the Hampel filter in the meantime, one is freely available on-line in the form of an EDN article I wrote in 2002, Scrub data with scale-invariant nonlinear digital filters. Also, comparisons with alternatives like the standard median filter (generally too aggressive, introducing unwanted distortion into the “cleaned” data sequence) and the center-weighted median filter (sometimes quite effective) are presented in Section 4.2 of the book Mining Imperfect Data mentioned above.



